Discretization invariance for the people
I wrote a blog post on discretization invariance — blog, repository, poster — for ICLR 2026 with the main intention of initiating a discussion on the purpose of this property. Do we need discretization invariance and why? The question is almost never discussed seriously, yet dozens of discretization-invariant architectures have been developed over the years.
The definition can be found in the blog, the poster and—an especially simple and lucid one—in the article Discretization Error of Fourier Neural Operators by Samuel Lanthaler, Andrew M. Stuart and Margaret Trautner. We call an architecture discretization-invariant if it can be specified in terms of continuous operations: \(\inf\), \(\sup\), integrals, (partial) derivatives, compositions, etc. Sure, if you do not use any discretization, your architecture will be discretization invariant!
In the blog, I gathered all the arguments for and against discretization invariance I could locate in the literature or concoct myself.
Arguments in favour of discretization invariance
- The discretization-invariant setup is theoretically natural. The use of PDEs forces one to consider function spaces; thus, from a theoretical standpoint, it is natural to set up the learning problem in a Banach space.
- Multiscale training. Discretization invariance is a form of “weight-sharing across different input resolutions”; for many architectures, one can use downsampled data to pre-train a model and later fine-tune it with high-resolution data.
- Reduced inference cost. In applications where a model must be evaluated repeatedly (e.g., sampling from diffusion models, guidance, MCMC, or energy-based models), one can resort to a coarser model most of the time.
- Hyperparameter optimisation. Hyperparameter optimisation can be performed with the help of a crude model, which can later be retrained on data with the desired resolution.
Arguments against discretization invariance
- Discretization invariance is an asymptotic condition. Formally, discretization invariance is only strictly achieved when the number of grid points tends to infinity.
- Only finite-resolution data is available. Training, evaluation, and deployment are always performed in a fixed-resolution setting. A good practical example is weather forecasting based on the ERA5 dataset.
- No generalisation is observed when the grid is refined. There is no “zero-shot super-resolution,” and one should not expect an architecture to generalise beyond the resolution seen during the training stage.
- Discretization invariance does not guarantee good performance. Any architecture can be made discretization-invariant with a suitable choice of encoder (e.g., scalar product, sampling) and decoder (e.g., interpolation, finite series as in DeepONet). Yet, the performance of such architectures can differ vastly.
Vox pop
At the conference, I asked people to vote for or against discretization invariance. Most people I talked to were not doing “AI for science,” likely with zero experience in operator learning for PDEs. People familiar with “AI for PDE” research were hedging. A few of them even refused to vote or took time to think and never returned to the poster (no offense taken, this is a huge conference).
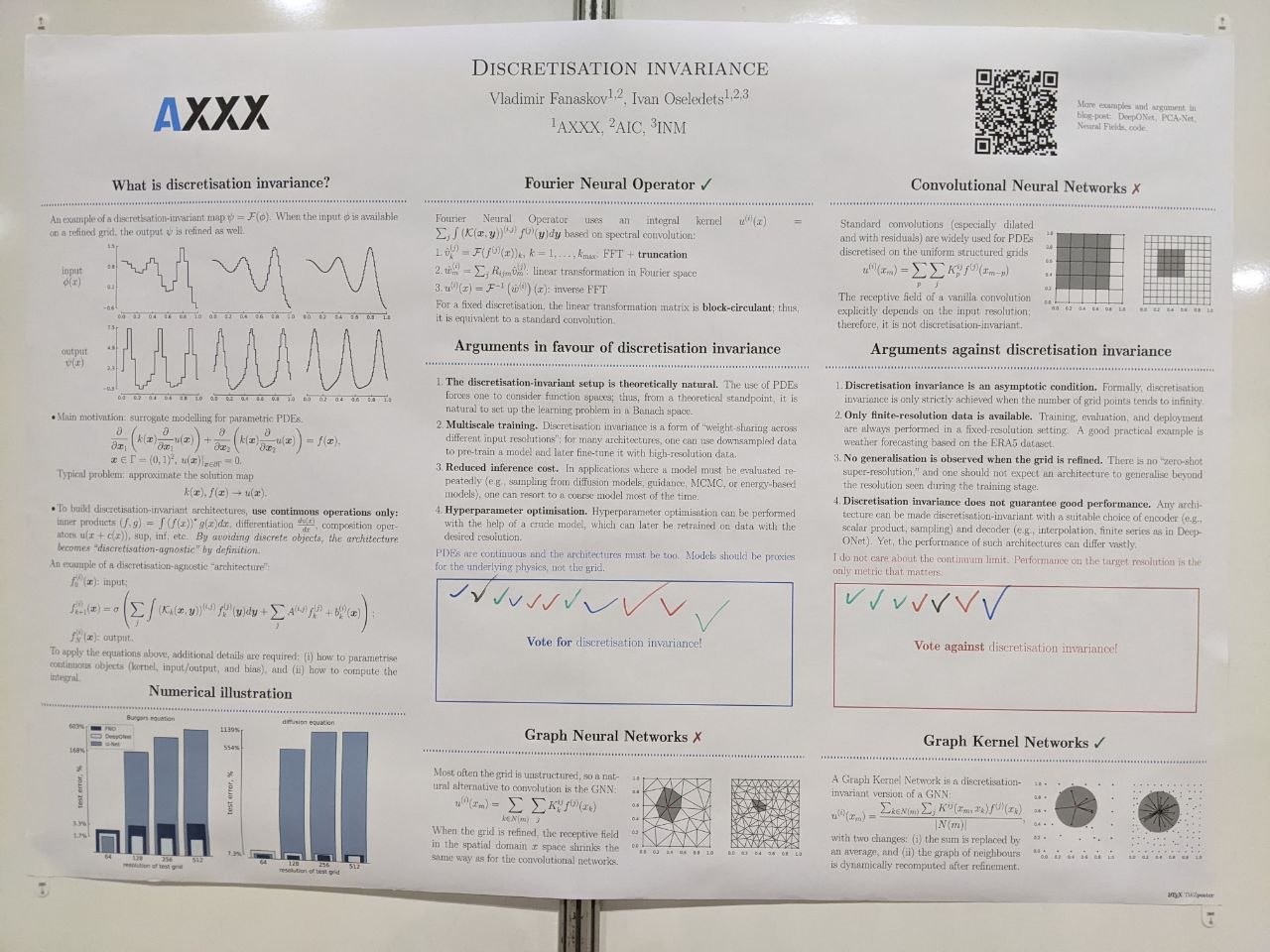
According to my small survey, discretization invariance is winning 11 to 7. We have reached a democratic consensus. Discretization invariance is officially the way to go.